

Egal ob (Super)-VideoCD, DVD, Internet oder digitaler Videorecorder. MPEG hat sich als "das" Distributionsformat für digitalen Film durchgesetzt. Doch nicht nur professionelle Studios setzen MPEG-Encoder zur Herstellung Ihrer Filme ein, auch viele Heimanwender benutzen vermehrt MPEG2 um ihre Filme platzsparend auf CD oder DVD zu archivieren. Während von einigen Jahren MPEG2-Codierung noch kostspielig und aufwändig war, genügt heute ein einfacher PC mit etwas Software um eine AVI-Datei in einen MPEG-Strom zu verwandeln. Doch MPEG2 ist nicht gleich MPEG2. Bei allen MPEG-Formaten ist nur der Decoding-Prozess genau spezifiziert. Dies bedeutet, dass nur festgeschrieben ist, wie ein fertiges MPEG-File aussehen muss, um korrekt wiedergegeben zu werden. Beim Encoding, also der eigentlichen Umwandlung des Films dürfen die Hersteller ihr eigenes Süppchen kochen, weshalb sich MPEG-Encoder oft stark in Qualität und Geschwindigkeit unterscheiden. Auch gibt es zahlreiche Parameter zu beachten, die über die Qualität des endgültigen Videos entscheiden. Aus diesem Grund muss man erst einmal die Grundlagen des Encodings verstanden haben, um zu wissen, mit welchen Parametern man die Qualität eines MPEG-Stroms entscheidend verbessern kann.
Was ist MPEG eigentlich?
MPEG steht für "Moving Pictures Experts Groups". Im allgemeinen Sprachgebrauch wird MPEG jedoch für eine allgemeine Formatbeschreibung verwendet, die eine effektive Speicherung von Video- und/oder Audiodateien beschreibt. Es gibt verschiedene MPEG-Standards, wobei die Standards MPEG1 und MPEG2 die Komprimierung von Videosignalen beschreiben.
MPEG1- und 2-Ströme eignen sich in erster Linie zur Distribution, d.h. sie sind dafür ausgelegt kleinstmögliche Videoströme zu erzeugen, die mit wenig Bandbreite gespeichert und übertragen werden können. Eine derartige Kompression ist dringend notwendig, wenn man einen Videofilm digital speichern will. Folgendes kleines Rechenbeispiel soll dies erläutern:
Bei einer Video-üblichen Auflösung von 720 x 576 Pixeln benötigt ein einziges, unkomprimiertes Bild bereits 1,2 Megabyte (720 x 576 mal 3 Byte für Rot, Grün und Blau). Bei der hierzulande gebräuchlichen PAL-Bildwiederholfrequenz von 25 Bildern pro Sekunde ergibt sich ein Speicherplatzverbrauch von 30 Megabyte pro Sekunde und eine Minute Video würde somit ca. 1,8 GB-Festplattenspeicher benötigen.
Das Ziel jeder Kompression liegt folglich darin, die Größe eines Videostroms dramatisch zu reduzieren, ohne die sichtbare Qualität zu verringern. In diesem Zusammenhang ist anzumerken, dass die Bildqualität und die notwendige Datenrate immer stark vom verwendeten Bildmaterial abhängen. So ist beispielsweise eine einfarbige Fläche sehr leicht zu komprimieren, da sich die benachbarten Pixel sehr ähnlich sind, während ein sehr detailreiches Bild bei gleicher Qualität eine weitaus höhere Datenrate benötigt. Nicht nur aus diesem Grund ist es notwendig, immer auf möglichst rauschfreie Aufnahmen zu achten, da ein Grieseln im Bild vom Kompressor als wichtiges Detail interpretiert wird. In der Folge kann die Kompression nicht mehr effektiv erfolgen. Viele MPEG-Encoder bieten zwar die Möglichkeit in gewissen Grenzen das Rauschen einer Aufnahme zu entfernen, jedoch geht dies immer zu Lasten der Bildschärfe.
In der Vergangenheit wurden zahlreiche Verfahren entwickelt, um Videoströme nun effektiv zu komprimieren. MPEG1/2 machen sich viele dieser Ideen zu nutze. Im einzelnen sind dies:
- Farbreduktion von RGB nach YUV
- Zerlegung des Bildes in einzelne Pixelblöcke
- Diskrete Cosinustransformation
- Quantisierung
- Huffmann-Codierung
- Interframe-Kompression
- Motion Compensation
- Two-Pass Encoding mit variable Bitraten
Bevor Sie mit den ersten Encoding-Schritten beginnen, sollten Sie daher zumindest grundsätzlich verstehen, was in den einzelnen Stufen der MPEG-Kompression vor sich geht. Sie werden dieses Wissen spätestens dann brauchen, wenn Sie sich näher mit den jeweiligen Parametern eines MPEG-Encoders auseinandersetzen wollen. Aus diesem Grund werden wir in diesem Artikel alle für Sie wichtigen Details möglichst einfach darstellen.
Farbreduktion von RGB nach YUV
Da das menschliche Auge auf Helligkeitsunterschiede viel sensibler reagiert als auf Farbunterschiede arbeiten Videogeräte seit je her mit einem anderen Farbraum. Dabei wird eine Farbe durch eine Helligkeitskomponente (Luma, Y) und zwei Farddifferenzkomponenten (Chroma, U+V) dargestellt. Das Y-Signal alleine entspricht einem Graustufenbild von dem abgeleiteten RGB-Bild. Es ist übrigens genau das Signal, welches man auf einem Schwarz/Weiß-Fernseher bei einem Farbfilm sehen würde. Die Farbinformation ist dagegen allein in den U- und V- Kanälen enthalten. Die Umwandlung zwischen RGB und YUV ist übrigens verlustfrei (wenn der Computer genügend genau rechnet). Da das Auge die Farben der einzelnen Pixel nicht so genau wahrnimmt, speichert man die Chroma-Komponenten nicht für jedes Pixel, sondern nur für die Hälfte, oder ein Viertel des gesamten Bildes. Dadurch wird die Datenrate des Videofilms bereits deutlich reduziert, ohne dass eine sichtbare Verschlechterung der Bildqualität eintritt.
In welchem Verhältnis dazu die Chroma-Komponenten U und V aufgenommen werden, bezeichnet eine Schreibweise, über den Sie sicherlich schon einmal gestolpert sind: YUV 4:2:2.
Die Zahlen hinter YUV beschreiben genau genommen die Vielfachen der Abtastrate. Für Sie genügt es zu wissen, dass diese Zahlen ein Verhältnis von Luma-Auflösung und Chroma-Auflösung darstellen. Im Klartext bedeutet YUV 4:2:2, dass die Helligkeit mit der vollen Auflösung aufgezeichnet wird, während die Farbkomponenten nur in halber Auflösung aufgenommen werden. Bei diesem Format erkennt in der Regel nicht einmal ein geschultes Auge den Unterschied zu einem RGB-Bild. Dafür ist der benötigte Speicherplatz nun schon ein drittel geringer. Vier Pixel im RGB-Farbraum (4 x R + 4 x G+ 4 x B) benötigen 12 Byte Speicherplatz während die selben vier Pixel als YUV 4:2:2 nur 8 Byte benötigen (4 x Y + 2 x U + 2 x V). In diesem YUV 4:2:2-Format arbeiten alle professionellen Videoformate.
Das MPEG-Format besitzt jedoch eine noch geringere Farb-Abtastung. Um den benötigten Speicherplatz weiter zu reduzieren, wird eine Abtastrate 4:2:0 verwendet. Hierbei werden alle zwei Pixel zwei Chrominanzwerte gespeichert, dies geschieht jedoch nur jede zweite Zeile. Nur die Luminanz wird weiterhin für jeden Pixel mit voller Auflösung gespeichert.
Die folgenden Abbildungen veranschaulicht die verschiedenen Abtastraten noch einmal grafisch:
RGB 24 Bit
| R G B | R G B | R G B | R G B |
| R G B | R G B | R G B | R G B |
| R G B | R G B | R G B | R G B |
| R G B | R G B | R G B | R G B |
YUV 4:2:2
| Y | Y U V | Y | Y U V |
| Y | Y U V | Y | Y U V |
| Y | Y U V | Y | Y U V |
| Y | Y U V | Y | Y U V |
YUV 4:2:0
| Y | Y U V | Y | Y U V |
| Y | Y | Y | Y |
| Y | Y U V | Y | Y U V |
| Y | Y | Y | Y |
Jede Zelle entspricht einem Pixel des Original-Bildes. Die Zelleninhalte beschreiben, welche Farbkomponenten bei welchem Abtastverfahren tatsächlich gespeichert werden.
Erstaunlicher weise ist das menschliche Auge so farbunempfindlich, daß die Abtastverfahren von MPEG immer noch äußerst gut aussehen können. Nur die geschultesten Augen erkennen an harten Farbkontrasten auf professionellen Studiomonitoren den Unterschied zwischen 4:2:2 und einer 4:2:0 Abtastung. Unsere Abbildung zeigt Ihnen, wie stark man den den Chroma-Farbraum reduzieren muss, bis das menschliche Auge störende Artefakte wahrnehmen kann.

Im ersten Bild können Sie ein Originalbild mit halbierter Chroma-Auflösung sehen. Auf dem zweiten Bild haben wir die Chroma-Auflösung auf 4:2:0 reduziert. Hier ist praktisch kein Unterschied zum Original zu erkennen. Selbst wenn man eine Chroma Auflösung von 4:1:0 wie in Abbildung 3 verwendet, halten sich die sichtbaren Artefakte noch in Grenzen. Erst bei Abbildung 4, die einer Chroma-Auflösung von 4:0,5:0 bemerkt das menschliche Auge deutliche Artefakte. Allerdings auch nur in den besonders farbempfindlichen roten Bereichen.
Da bei Fernsehern jedoch einige Farbsignale zur Synchronisation benötigt werden (zum Beispiel extreme Schwarz-Werte), wird in der digitalen Videobearbeitung der YUV-Farbraum noch etwas eingeschränkt und auf den sogenannten Y Cb Cr Raum übertragen
In diesem Farbraum steht pro Pixel nur eine Teilmenge der Pixelauflösung zur Verfügung (Y......16 bis 235, Cb und Cr....16 bis 240). Dies bedeutet, daß alle Farbwerte außerhalb der eben angegebenen Grenzen illegale Farben sind. So gibt es beispielsweise Schwarzwerte, welche schwärzer sind als das zugelassene Schwarz (alle Werte unter 16, sogenanntes Superblack). Für die MPEG-Bearbeitung ist es daher immer wichtig, in welchem Farbraum das Ursprungsmaterial vorliegt.
Zerlegung des Bildes in einzelne Pixelblöcke
Für die weitere Kompression wird das Bild in 8 x 8 große Pixelblöcke aufgeteilt. Warum gerade die Größe gewählt wurde, hat mathematische Hintergründe, die an dieser Stelle nicht interessieren. Wichtig ist für Sie nur, dass das Bild in diese Blöcke zerlegt wird, und diese einzeln weiter komprimiert werden. Einen schlechten Encoder (oder schlecht eingestellte Parameter) erkennt man schnell daran, dass diese Pixelblöcke nach dem Encoding im Videobild sichtbar sind.
Diskrete Cosinustransformation, Quantisierung und Huffmanncodierung
Im nächsten Schritt werden diese Pixelblöcke durch eine sogenannte Diskrete Cosinus Transformation (DCT) in spektrale Komponenten überführt. Wichtig ist nur, dass hierbei kein eigentlicher Verlust entsteht, sondern der Inhalt des Pixelblocks nur durch andere Zahlenpaare beschrieben wird, die sich für die weitere Kompression besser eignen. Der MPEG-Encoder versucht hier einfach die 8 x 8 Pixel in eine Form zu zerlegen, die sich durch Quantisierung effektiver speichern läßt.
Bei der Quantisierung werden -einfach gesagt- die Pixel nach Aspekten der menschlichen Sehgewohnheit grob gerundet. Diese "Sehgewohnheiten" sind in sogenannten Quantisierungstabellen zusammengefasst. Multipliziert man die spektralen Komponenten aus der DCT mit diesen Quantisierungstabellen entstehen hierbei zahlreiche Werte, die fast Null sind. Das besondere an diesen Nullen ist, dass diese Werte fast keine Information enthalten, die für das menschliche Auge relevant ist. Wie stark das Bild komprimiert wird hängt nur von der "Grobheit" der Rundung ab. Werden dabei viele ähnliche Zahlen (vor allem die besagten Nullen) erzeugt, können diese im letzten Schritt mit der Huffmann-Codierung speichersparend zusammengefasst werden. Die Huffmancodierung kann man sich dabei wie ein nachgeschaltetes WinZip-Programm vorstellen. Er komprimiert die entstandenen Daten verlustfrei um Speicherplatz zu gewinnen.
Die Details dieses Abschnitts können zwar ebenfalls die Qualität des MPEG-Stroms verändern, jedoch bringt eine Veränderung dieser Parameter nur etwas, wenn man die tiefen mathematischen Hintergründe der DCT und Quantisierung versteht. Außerdem lassen selbst die meisten Profis bei der Encodierung die Finger von diesen Parametern, weil man hier meistens die Ergebnisse eher verschlimmert als verbessert. Nur in wenigen Fällen macht hier ein Eingriff (wie bei Zeichentrickanimationen) wirklich Sinn. Ansonsten sei die DCT mit Quantisierung und Huffmancodierung an dieser Stelle nur der Vollständigkeit halber erwähnt. Viel entscheidender ist dagegen die..
Interframe-Kompression
Da bei einem Videofilm in der Regel aufeinander folgende Bilder eine große Ähnlichkeit besitzen, liegt es nahe auch mehrere, aufeinander folgende Bilder durch Kompression zusammen zu fassen.
Genau in diesem Prinzip liegt auch die Hauptstärke der MPEG-Kompression. Sie zerlegt die Bilder eines Videostroms in drei verschiedene Bildformate:
- I-Frames: Das sind Bilder, die nach dem oben beschriebenen Verfahren komprimiert wurden.
- P-Frames: Bilder, die aus vorhergegangenen I-Frames (oder auch P-Frames) berechnet werden.
- B-Frames: Bilder die sowohl aus vorhergegangenen als auch aus nachfolgenden I- oder P-Frames berechnet werden.
Die P- und B-Frames versucht MPEG2 mit einem definierten Algorithmus vorherzusagen. Dieser ist bereits in jedem Encoder definiert und muss nicht separat gespeichert werden. Natürlich trifft die Vorhersage des nächsten oder vorherigen Bildes niemals hundertprozentig zu. Jedoch ist die Differenz zwischen der Vorhersage und dem tatsächlichen Bildinhalt meistens nicht sehr groß, da sich aufeinander folgende Bilder ja meistens sehr ähnlich sind. Daher muss folglich nur die Differenz zwischen der Vorhersage und dem tatsächlichen Bildinhalt gespeichert werden, weshalb P und B Frames sehr wenig Speicherplatz beanspruchen.

Eine typische GOP-Struktur eines MPEG-Streams: Nur in den I-Frames werden komplette Bilder abgespeichert. Die P- und B-Frames enthalten nur die Unterschiede zwischen den einzelnen Bildern und benötigen daher weitaus weniger Speicherplatz.
Für die Qualität des endgültigen Videos ist es daher von starker Bedeutung, wie diese I,P, und B-Frames angeordnet sind. Die Gesamtlänge einer Folge von I-P-B-Frames wird GOP (Group of Pictures) genannt. Bei Szenen, die aufeinander folgende Bilder ohne starke Ähnlichkeit beinhalten, ist die Auswahl der GOP Struktur von großer Bedeutung. Beispielsweise bei schnellen Schnitten oder Schwenks zeigen sich schnell sichtbare Bildstörungen, wenn die GOP-Struktur für diese Szene falsch gewählt wurde.
Motion Compensation
Zur Vorhersage der P- und B- Frames benutzt MPEG2 äußerst ausgeklügelte Mechanismen. So versucht es einzelne Objekte im Videostrom zu erkennen und deren Bewegung vorherzusagen. Wird beispielsweise die Bewegung eines Autos bei einer stehenden Kamera gut erkannt sind die nachfolgenden P- und B-Frames sehr klein, da sich der Hintergrund ja nicht ändert und das Auto "nur weitergeschoben" werden muss. In der Praxis sind diese Berechnungen natürlich weitaus komplizierter.
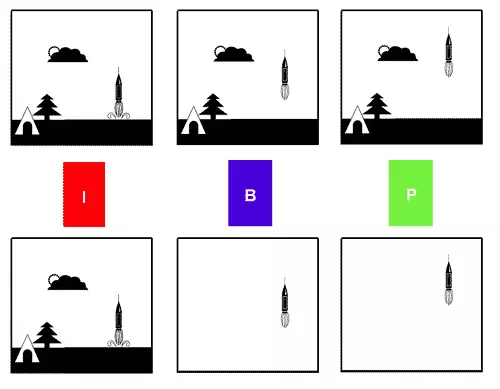
In der oberen Zeile sieht man (stark vereinfacht) den Start einer Rakete in Einzelbildern. Im darunter liegenden MPEG-Strom wird nur das erste Bild als ganzes in einem I-Frame gespeichert. Die folgenden P- und B-Frames speichern nur noch die Veränderung gegenüber dem I-Frame (In unserem Fall die Bewegung der Rakete).
Je mehr Zeit ein Codec hat, um solche bewegten Objekte zu finden, desto kleiner kann der Videostrom werden, weil die Prognosen genauer und die Differenzen kleiner werden. Aus diesem Grund erreichen Echtzeit-MPEG2-Codecs oft nicht die Qualität von besseren Software-Encodern, da diese sich mehr Zeit nehmen können Objekte und Bewegungen zu erkennen. Wie genau ein Encoder sucht läßt sich ebenfalls über Parameter bestimmen. Die Qualität des resultierenden Videostroms ist daher auch extrem von der Qualität der Suche abhängig. Wer ein optimales Ergebnis erzielen will und beim Encoding etwas Zeit erübrigen kann, kann auch hier seine Ergebnisse weiter optimieren.
Two-Pass Encoding mit variablen Bitraten
Da der Speicherplatz bei Videoströmen immer knapp ist, muss dem Encoder vor der Kompression mitgeteilt werden, wie groß der Videostrom maximal sein darf. Die Größe eines Videos wird durch die Bitrate bestimmt. Diese beschreibt, wieviel Bits pro Sekunde Video "verbraucht" werden dürfen.
Bei der Encodierung kann der Anwender in der Regel zwischen einer konstanten und einer variablen Bitrate wählen. Bei der konstanten Bitrate (CBR) steht dem Encoder eine fest vorgegebene Speicherbandbreite zur Verfügung, die er auf keinen Fall überschreiten darf. Benötigt eine Sequenz dabei mehr Speicherplatz als verfügbar, wird diese Sequenz einfach stärker komprimiert, was in manchen Szenen schnell zu sichtbaren Qualitätseinbußen führt. Die variable Bitrate (VBR) kann dagegen Speicher dynamisch verteilen. Benötigt eine Szene beispielsweise weniger Speicherplatz als die vorgegebene Bitrate, so kann der übrige Speicherplatz für eine spätere Szene "aufgehoben" werden. Die spätere Szene hat dann eine höhere Bitrate zur Verfügung als die geforderte Bitrate des gesamten Videos.
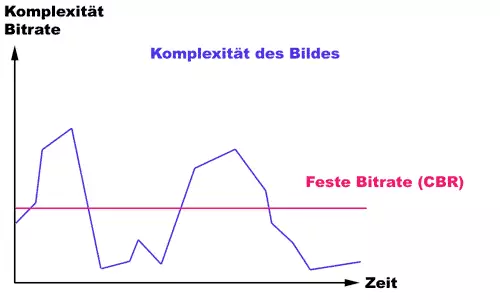
Die erste Abbildung zeigt das Verhalten des Encoders mit konstater Bildrate (CBR). Die blaue Linie stellt die Komplexität der einzelnen Videoframes dar. Aufgrund der konstanten Bitrate kann der liefert der Encoder bei sehr komplexen Bildern (Berge) zu wenig Datenrate, während bei einfachen Bildern die Datenrate unnötigerweise über den Tälern liegt und hier Bandbreite verschwendet wird.
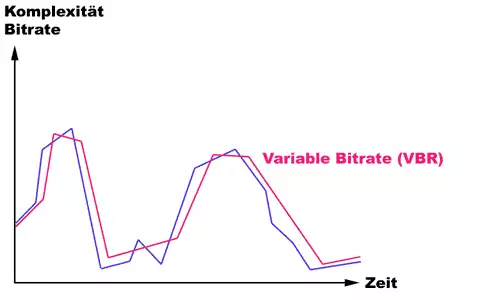
Die zweite Abbildung symbolisiert, wie sich die variable Bildrate an die Komplexität des Videostroms anpasst.
Die VBR bietet in den meisten Fällen eine bessere Bildqualität bei gleicher, durchschnittlicher Bitrate.
Um dieses Prinzip auch vollständig ausnützen zu können, muss der Encoder jedoch vorausschauend arbeiten können. In einem ersten Durchgang müssen erst einmal alle Szenen des Videos auf ihre Komplexität untersucht werden, wie viel Speicherplatz welche Szene voraussichtlich benötigen wird. In einem zweiten Durchgang kann dann die vorhandene Bandbreite (i.e. Bitrate) auf die einzelnen Szenen optimal verteilt werden.
Obwohl auch eine VBR in einem Durchgang denkbar ist, erhält der Anwender erst mit zwei Durchgängen die (theoretisch) optimale Qualität bei vorgegebener Bitrate. Allerdings dauert der Encoding-Prozess auf diesem Weg auch deutlich länger als One-Pass-Encodings.
Dies war in aller Kürze eine Einführung in die MPEG-Kompression. Viele Sachverhalte wurden aus didaktischen Gründen stark vereinfacht (MPEG-Profis mögen mir verzeihen). Dennoch sollte dieses Grundwissen ausreichend sein, um in einem späteren Artikel auf die wichtigsten Einstellungen bei der Erzeugung eines professionellen MPEG-Streams einzugehen.


















